
MV-SSM:突破多視角3D人體姿態估計的泛化困境
科技產業資訊室(iKnow) - 陳玟妤 發表於 2025年8月28日
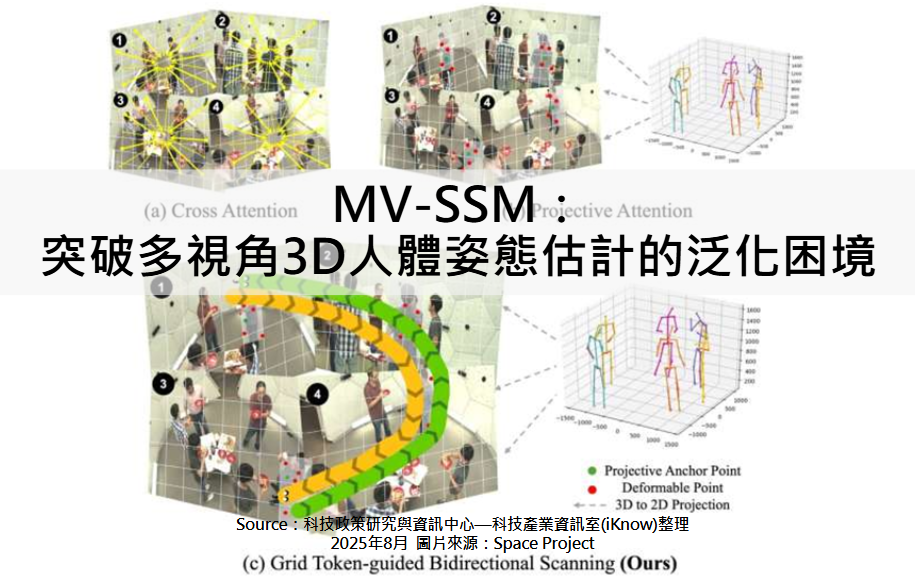
圖、MV-SSM:突破多視角3D人體姿態估計的泛化困境
3D人體姿態的精準估計一直是電腦視覺的重要挑戰,特別是在多視角情境下更顯複雜。雖然深度學習在2D關鍵點識別上已有顯著進展,並誕生了如 OpenPose、Mediapipe、YOLOPose 等模型,但從2D延伸到3D並非直接可行。當任務轉向在全球座標系中預測關節(x, y, z)時,即便採用多攝影機,問題依舊棘手。從單張影像推斷3D使得多視角3D多人物姿態長期受制於「泛化危機」,為此,卡內基美隆大學研究團隊於 CVPR 2025 提出了多視角狀態空間建模(MV-SSM, Multi-View State Space Modeling),首次將狀態空間模型(SSMs)引入該任務,顯著提升穩健性與泛化能力。
過去的研究多採取多階段流程,先在各視角獨立檢測2D關鍵點,再進行人物與關節匹配,最後透過攝影機參數進行三角測量。然而,這種流程的缺陷在於錯誤會層層放大,且在第一步就丟棄了大部分像素資訊,使後續完全依賴2D檢測器。為了避免錯誤累積,一些研究轉向端到端學習,試圖一次性完成整個任務。但此法不僅計算成本高,還涉及幾何三角測量如何以可微分形式建模的難題,更關鍵的是在新環境中泛化能力不足。
MV-SSM的核心在於提出 Projective State Space(PSS)區塊,結合投射注意力與狀態空間建模,以捕捉關節空間排列的廣義表示並有效融合多視角資訊。投射注意力能將關鍵點投影到不同視角錨點,再聚合周圍上下文以提升表徵效果。研究團隊同時改良了 Mamba 的掃描機制,提出 Grid Token-guided Bidirectional Scanning(GTBS),能更好編碼局部上下文與關節序列,逐步精煉關鍵點估計。整體架構是一個端到端可微分模型,以ResNet-50提取多尺度特徵,經由堆疊的PSS區塊逐層處理,最終利用可學習的幾何三角測量獲得3D關鍵點。與基於影片的Mamba著重於時間序列不同,MV-SSM專注於靜態多視角影像的空間序列建模,更好地捕捉視角間的內在幾何關係。
在實驗中,MV-SSM展現出優異的泛化能力並超越現有模型。在CMU Panoptic基準上,AP25達 93.5%,較VoxelPose提升9.5%,同時優於MvP與MVGFormer。在跨數據集評估中,MV-SSM在未經微調下於 Campus A1數據集PCP較MVGFormer提升15.3%,展現跨場景適應性。而在跨攝影機測試中,即使面對全新三攝影機配置,AP25仍較MVGFormer高出10.8%,且在跨配置的CMU3設定下,MV-SSM也比其他最先進模型提升7.0%。消融實驗則進一步證實PSS區塊、Mamba模組、GTBS機制以及幾何分支的重要性。
然而,MV-SSM仍有一定限制。與大多數現有方法相同,它假設攝影機參數已知。此外,當人物僅於單一視角可見時,模型準確度會明顯下降,導致其他視角的關鍵點缺失。未來研究可探索在單視角情境下提升表現,或利用生成模型合成缺失與遮擋的關鍵點,以改善適用性。
總體而言,MV-SSM透過在多視角輸入中建模關節空間序列,顯著提升了3D姿態估計的穩健性與泛化能力。這一突破不僅解決了長期困擾的泛化問題,也為擴增實境與虛擬實境、動畫製作、工業監控與安防等領域開啟了廣闊前景。(1052字;圖1)
參考資料:
More cameras, more problems? Why deep learning still struggles with 3D human sensing. TechXplore. 2025.08.12
MV‑SSM: Multi‑View State Space Modeling for 3D human pose estimation. CVPR. 2025/6
--------------------------------------------------------------------------------------------------------------------------------------------
【聲明】
1.科技產業資訊室刊載此文不代表同意其說法或描述,僅為提供更多訊息,也不構成任何投資建議。
2.著作權所有,非經本網站書面授權同意不得將本文以任何形式修改、複製、儲存、傳播或轉載,本中心保留一切法律追訴權利。
|